

Installing Hadoop HDFS data lake in Raspberry Pi 4 Ubuntu cluster

Introduction
Weeks ago I decided to start creating an experimental home size "Big data" system based on Apache Spark. The first step for it is to create a distributed filesystem where Apache Spark will read and write eveything.
HDFS is the Hadoop distributed filesystem which provides features like: fault detection and recovery, huge datasets, hardware at data, etc... despite it is a Hadoop ecosystem piece, it works nice as the data distributed filesytem for Apache Spark.
The HDFS filesystem will be installed in 8 RPIs of my 10 Raspberry Pi 4 cluster. To have a minimal storage size and decent speed I bought 8 extra SSD + 8 USB3 adaptors.


Installing HDFS
First of all, we are going to install a HDFS filesystem in a single node to test everything works in a simple way. I already have Ubuntu 18.04 server for Raspberry Pi 4 installed but I guess these steps won't differ too much if you have Ubuntu 20.04 server installed.
In my case pi3cluster is the RPI master host name and pi4cluster, pi5cluster, pi6cluster, pi7cluster, pi8cluster, pi9cluster, pi10cluster are the node host names. All my raspberry pis have declared a /etc/hosts file with all the name/ip pairs, you must do it as well if it's not already done:
192.168.1.32 pi3cluster
192.168.1.33 pi4cluster
192.168.1.34 pi5cluster
192.168.1.35 pi6cluster
192.168.1.36 pi7cluster
192.168.1.37 pi8cluster
192.168.1.38 pi9cluster
192.168.1.39 pi10cluster
1. Lets prepare our new 8 SSDs. After plugging them all into the Raspberry PI 4 USB3 ports, they become available as the /dev/sda device. Let's partition and format all of them. Repeat these commands in all of your RPIs:
sudo fdisk /dev/sda
#(select option n, new partition)
#(select option p, primary type)
#(select option w, write and exit)
# like this: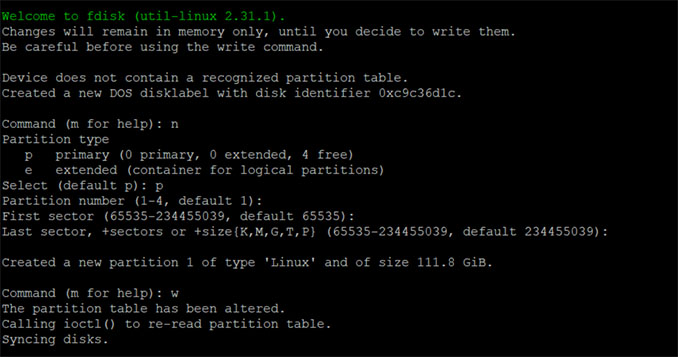
2. format /dev/sda1 new partition and create a new linux directory to mount it there (do it in all of your RPIs)
sudo mkfs.ext4 /dev/sda1
sudo mkdir /mnt/hdfs
3. Edit your linux filesystem list and add the new one (do it in all of your RPIs)
sudo nano /etc/fstab
4. Once you have nano displaying it, add this line at the end of the file (do it in all of your RPIs):
/dev/sda1 /mnt/hdfs ext4 defaults 0 0
5.refresh your linux filesystem mounting points:
sudo mount -av
6. Install Java and wget packages, here: Hadoop Java Versions documentation you can find which version is recommended. (do it in all of your RPIs)
sudo apt install openjdk-8-jdk-headless wget
7. Add a new system user for your hadoop hdfs (do it in all of your RPIs)
sudo adduser hadoop
8. Download and copy the latest hadoop available package and install it only in your master RPI
cd ~
wget https://www-eu.apache.org/dist/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz
tar xzf hadoop-3.2.1.tar.gz
rm hadoop-3.2.1.tar.gz
sudo mkdir /opt
sudo mv hadoop-3.1.2 /opt/hadoop
sudo chown hadoop:hadoop -R /opt/hadoop
9. Create hadoop hfds data folders (do it in all of your RPIs)
sudo mkdir -p /mnt/hdfs/datanode
sudo mkdir -p /mnt/hdfs/namenode
sudo chown hadoop:hadoop -R /mnt/hdfs
10. Login as hadoop user and create the ssh key (do it in all of your RPIs)
sudo -i
su hadoop
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
11. From your master node, logged in as hadoop user, authorise your master to all the other nodes adding your master ssh key as an authorised one, repeat this command for all your nodes replacing <ip> by your node ip
$ cat ~/.ssh/id_rsa.pub | ssh hadoop@<ip> 'cat >> .ssh/authorized_keys'
12. Add all environment variables needed by hadoop in this file /home/hadoop/.bashrc (do it in all of your RPIs)
export HADOOP_HOME=/opt/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
after adding those lines, reload your variables
source ~/.bashrc
13. Add Hadoop to your PATH, edit /home/hadoop/.profile. Add this line at the end of the file (do it in all of your RPIs)
PATH=/opt/hadoop/bin:/opt/hadoop/sbin:$PATH
14. Set JAVA_HOME in the hadoop environment config file
nano $HADOOP_HOME/etc/hadoop/hadoop-env.shAdd export java_home=/usr/lib/jvm/java-8-openjdk-arm64/bin/java like:

15. Let's start changing the hadoop cluster configuration files, you can find all texts to copy and paste here hdfs-config.txt. Add the configuration section to core-site hadoop file
nano $HADOOP_HOME/etc/hadoop/core-site.xml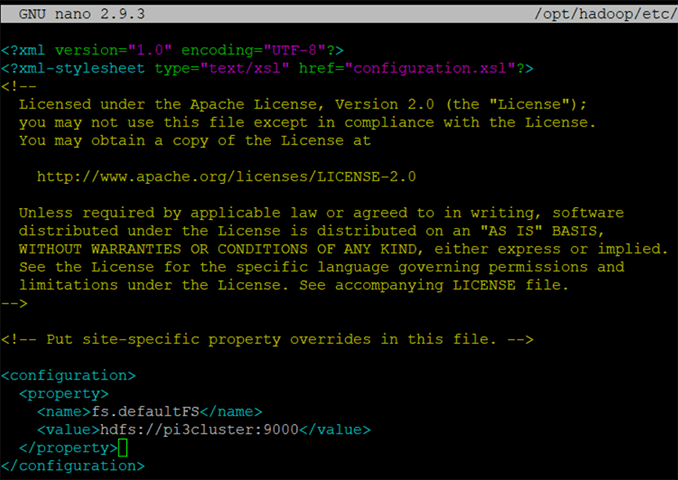
16. Add the configuration section to hdfs-site hadoop file
nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml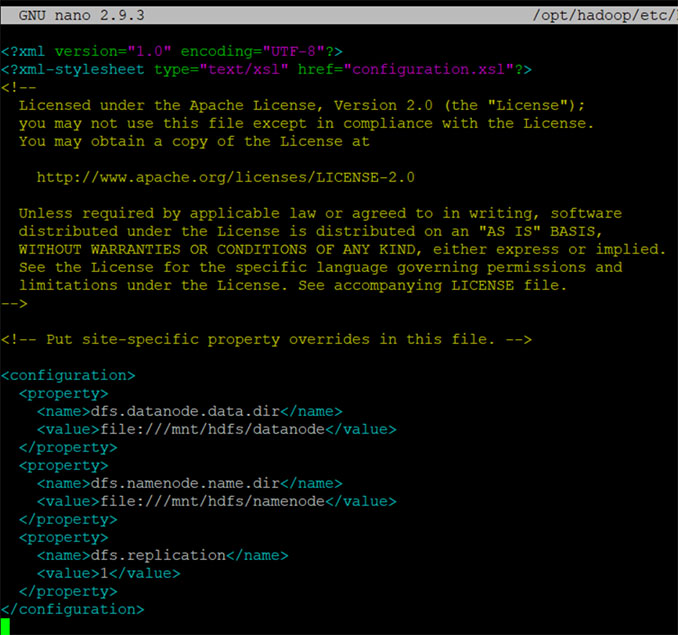
17. Add the configuration section to mapred-site haddop file
nano $HADOOP_HOME/etc/hadoop/mapred-site.xml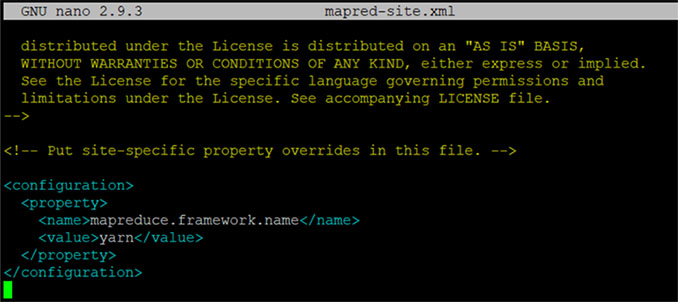
18. Add the configuration section to yarn-site hadoop file
nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
19. After everything is configured and the SSD is partitioned and mounted, we can format the HDFS (only the master RPI)
/opt/hadoop/bin/hdfs namenode -format -force
20. Let's start HDFS filesystem and do some operations to check everything works fine
cd $HADOOP_HOME/sbin/
./start-dfs.sh
./start-yarn.sh
hadoop fs -mkdir /test_folder
hadoop fs -ls /
21. Check you can see all Hadoop info websites: (A) services web, (B) cluster info web, (C) hadoop node web, and (D) check the "test_folder" you created is there too
http://<your server ip>:9870/
http://<your server ip>:8042/
http://<your server ip>:9864/
http://<your server ip>:9870/explorer.html(A)

(B)

(C)
(D)

21. If you want to restart the server later, use these commands
cd $HADOOP_HOME/sbin/
stop-all.sh
start-all.sh
From single node to HDFS cluster
After checking Hadoop HDFS working fine as a single node, It's time to extend it to all our capable nodes creating a HDFS cluster.
22. Let's start changing the hadoop cluster configuration files again, leave them as they are shown in the pictures. You can find all texts to copy and paste here hdfs-cluster-config.txt. Remember to change my RPI host names like pi3cluster to your specific names.
nano $HADOOP_HOME/etc/hadoop/core-site.xml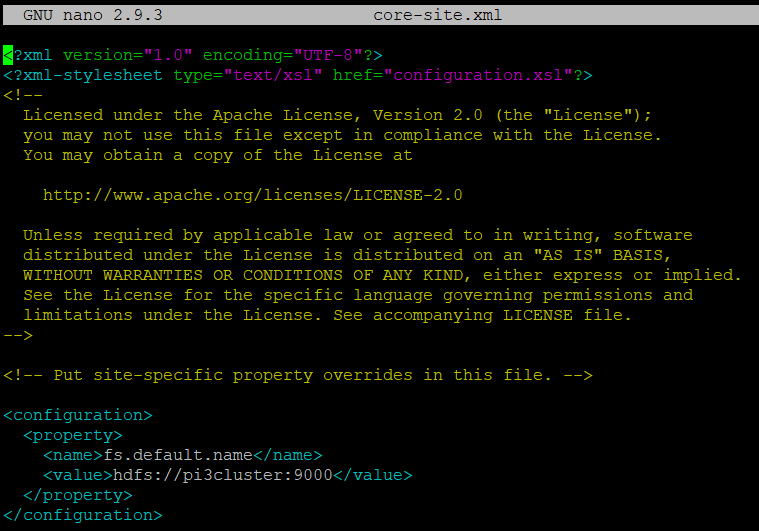
nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
23. In your cluster make sure all services are stopped, delete all files from before
cd $HADOOP_HOME/sbin/
stop-all.sh
$ clustercmd rm –rf /opt/hadoop_tmp/hdfs/datanode/*
$ clustercmd rm –rf /opt/hadoop_tmp/hdfs/namenode/*
24. Logged in as hadoop user, create master and workers files inside hadoop configuration.
nano /opt/hadoop/etc/hadoop/master
nano /opt/hadoop/etc/hadoop/workersIn master file, add only one line, your master RPI host name, in my case it looks like:
pi3cluster
In workers file, add as many lines as you need listing all the host names of your RPI nodes, in my case it looks like:
pi4cluster
pi5cluster
pi6cluster
pi7cluster
pi8cluster
pi9cluster
pi10cluster
25. In your master node, and ONLY there, format your name node. IMPORTANT: backup your hdfs files folder if you have important files there from before, they will be deleted.
hdfs namenode -format -force
26. From your single master node, tar your hadoop home to a shared network folder or a pen drive
sudo tar -czvf /mnt/shared-network-folder/hadoop.tar.gz /opt/hadoop
27. In all your new raspberry pi cluster nodes, extract the tar file in the same place and force the ownership to hadoop user
sudo tar -xzvf /mnt/shared-network-folder/hadoop.tar.gz -C /opt/
sudo chown hadoop:hadoop -R /opt/hadoop
28. From your master node, logged in as hadoop user start the HDFS system
start-dfs.sh && start-yarn.sh
29. You should be able to see your multinode hadoop HDFS distributed filesystem, browse this URL: http://<your-master-ip-or-node-name>:9870/dfshealth.html#tab-datanode